
Czym są kolekcje…
Zacznijmy od dowiedzenia się czym są kontenery – taka nazwa panuje ogólnie w programowaniu, zaś w Javie nazywamy je kolekcjami. Kolekcje to nic innego jak struktury danych, które umożliwiają nam przechowywanie danych (dowolnych obiektów np. lista osób) i udostępniają nam przeróżne metody np.:
- Dodawanie do kolekcji
- Usuwanie z kolekcji
- Wyszukiwanie w kolekcji
- Czyszczenie kolekcji
Złożoność obliczeniowa tych operacji różni się od implementacji danej struktury danych.
W programowaniu mamy wiele rodzajów kontenerów, z których każdy z nich jest wykorzystywany do odpowiednich celów. Najbardziej popularne kontenery to:
- Lista
- Stos
- Mapa
- Kolejka
- Tablica
- Zbiór
Kolekcje w javie
W javie w bardzo łatwo sposób możemy korzystać z kolekcji, które dostarcza nam język poprzez import pakietu util. Wystarczy, więc dodać poniższą linię kodu i mamy dostęp do wszystkich kolekcji…
import java.util.*;
Zanim jednak pokażę Ci różnice między kolekcjami oraz przytoczę przykłady ich użycia zatrzymajmy się chwilę przy drzewie hierarchii kolekcji w javie.
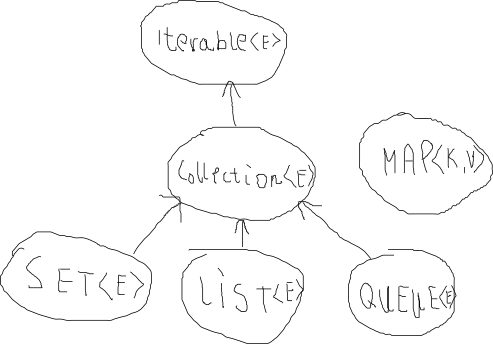
Zacznijmy omawianie interfejsów od samej góry.
Iterable
Jest to bardzo prosty interfejs, który zawiera w sobie tylko iterator. Dzięki temu, że Collection implementuje ten interfejs mamy możliwość użycia pętli foreach` na używanych przez nas kolekcjach. Upraszcza to bardzo kod aplikacji oraz skraca zapis. Spójrzmy jaka jest różnica podczas używania pętli for, a pętli foreach.
Użycie pętli for:
for(int i=0;i<list.size(); i++){
System.out.println(list.get(i));
}
Użycie pętli foreach:
for(Object element : list){
System.out.println(element);
}
Co prawda pętla foreach nie jest niezastąpiona, musimy np. z niej zrezygnować podczas usuwania elementów z kolekcji iterując po niej.
Collection
Collection jest interfejsem, który jest implementowany przez wszystkie kolekcje oprócz mapy. Zapewnia to, że każda implementacja interfejsu Collection umożliwia nam takie operacje jak:
- Dodawanie elementów
- Usuwanie elementów
- Sprawdzanie czy jest pusta kolekcja
- Czy kolekcja zawiera element
- Usuwanie elementów, które nie są przekazane w kolekcji jako argument
- Konwersja do tablicy
Warto, więc implementować interfejs Collection jeżeli mamy zamiar tworzyć własną kolekcje. Dzięki temu będziemy mieli pewność, że stworzona przez nas kolekcja zawiera podstawowe operacje
<E>
Jak zdążyłeś zauważyć przy każdym interfejsie w hierarchi drzewa występuje <E>, a w przypadku mapy nawet <K, V>. Jest to nic innego jak typy generyczne, jeżeli ktoś programował w języku C++ to z pewnością zna pojęcie szablonów (template) – chodzi właśnie o to samo.
Dzięki typom generycznym w javie zachodzi polimorfizm parametryczny, oznacza to, że klasy mogą być bardziej elastyczne. Ja osobiście odczuwam, że typy generyczne mają swoje największe zastosowanie w kolekcjach.
Typy generyczne w kolekcjach są bardzo ważne, dzięki nim w każdej kolekcji możemy przechowywać obiekty dowolnego typu. Nieważne czy będą to obiekty typu: User, Integer, Boolean, File – wszystkie te obiekty możemy przechowywać w kolekcjach.
Gdy jeszcze nie bylo typów generycznych w javie, można było obejść ten problem poprzez przechowywanie w kolekcjach typu Object, po których dziedziczy każdy obiekt. Jednak korzystając z takiego rozwiązania, do kolekcji można byłoby wstawiać elementu w ogóle różnego typu – powiązane ze sobą tylko przez Object. Cóż to za sens wrzucać buty do kosza z jabłkami… No chyba że to jakiś kosz na śmieci.
Przykłady i zastosowanie
Zajmijmy się teraz kolejnymi interfejsami, które są pokazane na powyższym drzewie hierarchii. Omówię ich zastosowanie, podam przykład zastosowania oraz pokażę przykładową implementację jaką można osiągnąć w javie.
List
Na początek, zajmijmy się interfejsem List. Jest to interfejs, która umożliwia nam przechowywanie danych jak w zwykłej tablicy. Do każdego elementu możemy bez problemu odwołać się poprzez index. Jeżeli działa ona jak zwykła tablica to jakie są jej zalety?
Największą zaletą jest to, że podczas korzystania z list nie musimy się martwić o jej rozmiar. To już konkretne implementacje list zajmują się tym, aby nigdy nie wyjść poza zakres tablicy. Dodatkowo lista posiada metodę, która umożliwia nam wstawienie elementu pod konkretny index i sama załatwia już kwestię przesuwania elementów. Dostępna jest również metoda subList, która umożliwia nam zwrócenie listy utworzonej z elementów znajdujących się w podanym zakresie.
Jest, aż dziesięć możliwości implementacji interfejsu List:
- ArrayList
- LinkedList
- AbstractList
- AbstractSequentialList
- AttributeList
- CopyOnWriteArrayList
- RoleList
- RoleUnresolvedList
- Stack
- Vector
My zajmiemy się implementacją dwóch pierwszych tzn. : ArrayList i LinkedList. Są bardzo często używane i warto znać różnice występujące między nimi. Polecam zapoznać się również z dwoma ostatnimi implementacjami, otworzyć dokumentację i wykorzystać je w praktyce.
LinkedList vs ArrayList
Zagłębmy się trochę w implementację tych dwóch list. Jak sama nazwa wskazuje LinkedList oznacza, że są wykorzystane powiązania między elementami, ArrayList zaś informuje, że jest wykorzystana tablica.
I tak właśnie jest, gdy zerkniemy do obu kodów. Jednak czy coś nam to mówi? Czy mówimy nam to może, jakie różnice występują między tymi dwiema listami? Otóż te różnicę bardzo warto znać, aby nie dać klapy podczas pisania większej aplikacji, gdzie są wykonywane tysiące operacji.
Wyszukiwania
Ze względu, że ArrayList korzysta z tablic to dostęp do danych jest natychmiastowy tzn. O(1), ponieważ używamy indeksów.
W przypadku LinkedList, gdzie elementy są powiązane ze sobą (każdy zawiera informację tylko o poprzednim i następnym elemencie w liście), aby znaleźć element złożoność obliczeniowa jest równa O(n). W przypadku, gdy element jest na początku listy wszystko będzie ok, co jeśli wyszukiwany element będzie 100000 elementem w liście?
Usuwanie
Usuwanie – tym razem szybciej wykonuje to LinkedList. Wystarczy jej O(1), aby usunąć dany element, ponieważ do usunięcia wystarczy zmienić dwa adresy. Czyli element poprzedni elementu usuwanego musi wskazywać na element następny elementu usuwanego i vice versa. Trochę skomplikowane, lecz wystarczy spojrzeć na obrazek poniżej.

W przypadku usuwania elementu w ArrayList operacja się ta może znacznie wydłużyć. Dzieje się tak, ponieważ jesteśmy zmuszeni do przesunięcia wszystkich kolejnych elementów występujących po usuwanym elemencie o jeden index w dół.
Wszystko szybko pójdzie, jeżeli usuwamy ostatni element z listy, ponieważ nie musimy nic przesuwać. Jednak najgorszym scenariuszem jest usuwanie pierwszego elementu, złożoność takiej operacji to aż O(n).
Wstawianie
Zastanówmy się teraz nad wstawianiem elementów do obu tych list. Weźmy pod uwagę wiedzę, jaką mamy już o usuwaniu elementów z tablicy. Czy jakieś wnioski się nasuwają?
Wstawianie działa podobnie jak usuwanie, musimy bowiem wykonać podobne operacji w obu przypadkach.
Gdy dodajemy element na końcu ArrayList wszystko jest ok, w końcu nie ma żadnych konfliktów. Jednak jesteśmy zmuszeni do dodania elementu na początku listy, i co teraz? Pierwszy index listy jest zajęty, skoro musi być pusty musimy przesunąć wszystkie elementy w “górę”. I o to w ten sposób złożoność obliczeniowa to O(n) – czyli niezbyt dobrze.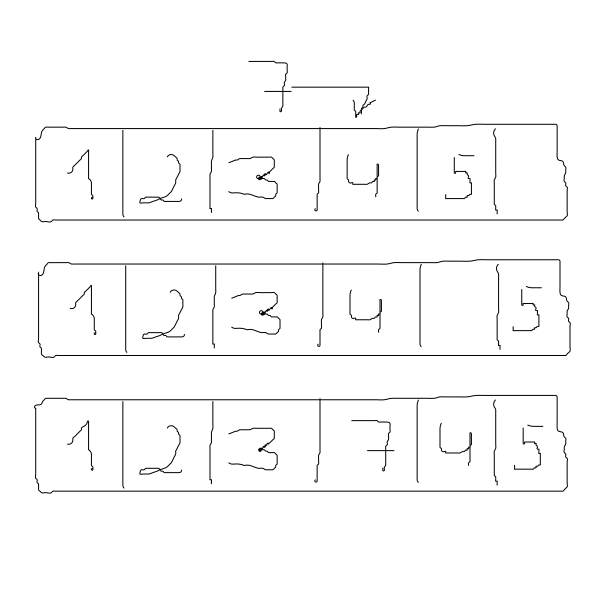 Sprawdźmy jak sytuacja w przypadku LinkedList, skoro usuwanie i wstawianie w ArrayList dawało podobne rezultaty to możemy się domyślać, że ta sama relacja zachodzi w przypadku LinkedList. Zgadza się, wstawianie do LinkedListy jest tak samo szybkie jak usuwanie, w końcu musimy tylko zmienić wskazywanie elementów pomiędzy nowym elementem i tak otrzymujemy O(1).
Sprawdźmy jak sytuacja w przypadku LinkedList, skoro usuwanie i wstawianie w ArrayList dawało podobne rezultaty to możemy się domyślać, że ta sama relacja zachodzi w przypadku LinkedList. Zgadza się, wstawianie do LinkedListy jest tak samo szybkie jak usuwanie, w końcu musimy tylko zmienić wskazywanie elementów pomiędzy nowym elementem i tak otrzymujemy O(1).

Win or lose
Kto wygrał to starcie? Ano nikt, jest remis. To my musimy wybrać kto wygra w naszym starciu (czyt. wyborze listy do konkretnej sytuacji).
Wnioski są proste, powinniśmy wykorzystywać LinkedList do list, których operacją dominującą będzie wstawianie oraz usuwanie elementów. Wtedy nawet podczas miliona operacji wstawiania/usuwania aplikacja będzie miała możliwość działać szybciej.
Jednak w przypadku, gdy mamy listę, którą bardzo często przeszukujemy warto wybrać ArrayList. Dzięki zastosowaniu tablic mamy dostęp do danych O(1) – czyli błyskawicznie.
Czasami będziesz się zastanawiać, które rozwiązanie będzie lepsze do danej sytuacji. W końcu operacja wyszukiwania często przynosi ze sobą następną operację czyli usuwanie elementu – jest to jednak gra wyboru i trzeba się poważnie zastanowić, która implementacja zrobi to szybciej.
Zastosowanie
Znasz już różne możliwe implementacje interfejsu List oraz znasz bardzo ważne różnice występujące między Linked i Array Lists. Czas przejść do prawdziwych przykładu i do ulubionego pisania kodu. Ze względu, że Linked i Array są najczęściej stosowanymi listami to właśnie na nich pokażę zastosowanie.
LinkedList
Stwórzmy listę, w której będziemy przechowywać listę uczestników dużego wydarzenia. Przyjmijmy, że operacja usuwania będzie wykonywana tutaj części – np. organizator wydarzenia zdecyduje, że jednak wydarzenie jest tylko dla osób pełnoletnich.
Na początek zdefiniujmy sobie model uczestnika wydarzenia, skorzystamy z niego również w kolejnym przykładzie.
package pl.maniaq.models;
import java.util.Objects;
public class Participant {
private static int PARTICIPANT_ID = 0;
private int id;
private String name;
private int age;
public Participant(String name, int age){
this.name = name;
this.age = age;
this.id = PARTICIPANT_ID++;
}
public int getId(){
return id;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Participant)) return false;
Participant that = (Participant) o;
return getId() == that.getId() &&
getAge() == that.getAge() &&
Objects.equals(getName(), that.getName());
}
@Override
public int hashCode() {
return Objects.hash(getId(), getName(), getAge());
}
@Override
public String toString() {
return "Participant{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
Nic skomplikowane, model przechowuje podstawowe informacje o uczestniku: ID, imię oraz jego wiek. Dodatkowo zaimplementowałem metodę toString(), aby wyświetlać informację o uczestniku oraz metody equals() oraz hashCode(). Obie te metody warto implementować, gdy są wykorzystywane w kolekcjach, więcej o nich powiem w innym wpisie.
Zajmijmy się teraz wykorzystaniem tego modelu w LinkedLiście.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.*;
public class Linked {
public static void main(String[] args) {
List<Participant> participants = new LinkedList<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19),
new Participant("Ula", 16)
));
}
}
Utworzyłem listę uczestników przy pomocy implementacji LinkedList. Jak może zauważyłeś jako typ użyłem interfejsu List, zrobiłem tak ponieważ nasza lista jest bardziej uniwersalna skoro korzysta z interfejsu. Dodatkowo jeżeli będziemy chcieli zmienić LinkedList na ArrayList to zrobimy to w jednym miejscu. Jako argument przekazałem kolekcję, na podstawie której zostanie utworzona lista uczestników, jest to czytelniejsze rozwiązanie. Oczywiście możemy też dodać kolejnych uczestników przy pomocy metody add(E element).
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.*;
public class Linked {
public static void main(String[] args) {
List<Participant> participants = new LinkedList<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19),
new Participant("Ula", 16)
));
participants.add(new Participant("Kamil", 16));
participants.add(new Participant("Alex", 21));
}
}
Przejdźmy teraz do filtrowania niepełnoletnich uczestników i usunięcia ich.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.*;
public class Linked {
public static void main(String[] args) {
List<Participant> participants = new LinkedList<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19),
new Participant("Ula", 16)
));
participants.add(new Participant("Kamil", 16));
participants.add(new Participant("Alex", 21));
for(Iterator<Participant> participantIterator = participants.iterator(); participantIterator.hasNext(); ){
Participant participant = participantIterator.next();
int participantAge = participant.getAge();
boolean ageSmallerThan18 = participantAge < 18;
if(ageSmallerThan18){
participantIterator.remove();
}
}
}
}
Tak jak wspominałem wcześniej, usuwanie elementów z kolekcji podczas iterowania nie jest możliwe przy użyciu pętli foreach. W tym celu musimy zdefiniować iterator (pętla foreach również z niego korzysta) i poprzez metodę remove() usunąć dany element. Więcej na temat iteratora możesz przeczytać tutaj.
Dodajmy jeszcze wyświetlenie uczestników przed i po usunięciu, aby zobaczyć efekty naszych działań.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.*;
public class Linked {
public static void main(String[] args) {
List<Participant> participants = new LinkedList<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19),
new Participant("Ula", 16)
));
participants.add(new Participant("Kamil", 16));
participants.add(new Participant("Alex", 21));
System.out.println("Lista wszystkich uczestników: ");
for (Participant participant:participants
) {
System.out.println(participant.toString());
}
for(Iterator<Participant> participantIterator = participants.iterator(); participantIterator.hasNext(); ) {
Participant participant = participantIterator.next();
int participantAge = participant.getAge();
boolean ageSmallerThan18 = participantAge < 18;
if (ageSmallerThan18) {
participantIterator.remove();
}
}
System.out.println("Lista uczestników pełnoletnich: ");
for (Participant participant:participants
) {
System.out.println(participant.toString());
}
System.out.println("Liczba uczestników: "+participants.size());
}
}
Dodatkowo użyłem metody size(), która zwraca rozmiar listy. Rezultat działania takiego kodu wygląda tak:
Lista wszystkich uczestników:
Participant{id=0, name='Franek', age=15}
Participant{id=1, name='Edek', age=18}
Participant{id=2, name='Olek', age=19}
Participant{id=3, name='Ula', age=16}
Participant{id=4, name='Kamil', age=16}
Participant{id=5, name='Alex', age=21}
Lista uczestników pełnoletnich:
Participant{id=1, name='Edek', age=18}
Participant{id=2, name='Olek', age=19}
Participant{id=5, name='Alex', age=21}
Liczba uczestników: 3
Ze względu, że jest to wpis, który ma pokazać działanie wszystkich kolekcji, a nie skupiać się na konkretnych implementacja zachęcam Cię do zajrzenia i przetestowania metod klasy LinkedList.
ArrayList
Implementacja ArrayList będzie krótsza, w końcu nie różni się zbytnio od implementacji LinkedListy. Musimy teraz zwrócić, że bardzo szybko wykonywane są operacje wyszukiwania, wypiszmy, więc wszystkie osoby niepełnoletnie z naszej listy.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.*;
public class Array {
public static void main(String[] args) {
List<Participant> participants = new ArrayList<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19),
new Participant("Ula", 16)
));
participants.add(new Participant("Kamil", 16));
participants.add(new Participant("Alex", 21));
System.out.println("Lista wszystkich uczestników niepełnoletnich: ");
for (Participant participant:participants
) {
int participantAge = participant.getAge();
boolean ageIsSmallerThan18 = participantAge < 18;
if(ageIsSmallerThan18){
System.out.println(participant.toString());
}
}
}
}
Rezultat działania takiego kodu będzie następujący:
Lista wszystkich uczestników niepełnoletnich:
Participant{id=0, name='Franek', age=15}
Participant{id=3, name='Ula', age=16}
Participant{id=4, name='Kamil', age=16}
Zachęcam Cię do przetestowania wszystkich metod, które udostępnia nam klasa ArrayList.
Set
Przejdźmy teraz do opisu interfejsu Set. Set jest prawie zwykłym zbiorem obiektów, wyróżnia go tylko jedna rzecz – wszystkie elementy w Set muszą być unikalne. W skrócie nie pozwala on na przechowywanie dwóch takich samych obiektów. Podczas dodawania musi, więc wystąpić sprawdzanie obiektów – jest wykonywane to za pomocą metody equals.

Interfejs Set jest implementowany przez wiele klas:
- AbstractSet
- ConcurrentSkipListSet
- CopyOnWriteArraySet
- EnumSet
- JobStateReasons
- LinkedHashSet
- HashSet
- TreeSet
My zajmiemy się dwoma ostatnimi – czyli: HashSet oraz TreeSet.
Zaimplementujmy sobie teraz te dwie klasy, skorzystajmy z poprzedniego modelu Participant. Wykorzystajmy zbiór Set, aby uniemożliwić uczestnikowi kilkukrotne zapisanie się na wydarzenie.
HashSet
HashSet jest w sumie najprostszą implementacją interfejsu Set. Warto pamiętać, że jest zbudowany na HashMap dzięki czemu operacje takie jak: add, remove, contains oraz size mają złożoność obliczeniową O(1). Dodatkowo HashSet umożliwia dodanie null do zbioru.
Rozpocznijmy od małych zmian w modelu Participant, musimy usunąć ID, które ciągle się zmienia – jeżeli go zostawimy to uczestnik o tym samym imieniu i wieku zostanie dodany do zbioru, ponieważ w obu obiektach będzie różne ID. Klasa Participant wygląda teraz tak:
package pl.maniaq.models;
import java.util.Objects;
public class Participant {
private String name;
private int age;
public Participant(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Participant)) return false;
Participant that = (Participant) o;
return getAge() == that.getAge() &&
Objects.equals(getName(), that.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getAge());
}
@Override
public String toString() {
return "Participant{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Przejdźmy teraz do napisania implementacji HashSet.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Set;
public class Hash {
public static void main(String[] args) {
Set<Participant> participants = new HashSet<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19)
));
participants.add(new Participant("Franek", 15));
participants.add(new Participant("Olek", 19));
participants.add(new Participant("Ula", 16));
System.out.println("Lista wszystkich uczestników");
for (Participant participant:participants
) {
System.out.println(participant.toString());
}
System.out.println("Liczba uczestników: "+participants.size());
}
}
Po uruchomieniu programu otrzymujemy taki rezultat:
Lista wszystkich uczestników
Participant{name='Edek', age=18}
Participant{name='Franek', age=15}
Participant{name='Olek', age=19}
Participant{name='Ula', age=16}
Liczba uczestników: 4
Jak zauważyliśmy, w main dodaliśmy 6 obiektów do zbioru Set, jednak tylko 4 zostały wyświetlone. Stało się tak oczywiście, ponieważ zostały wykluczone duplikaty, które są określane na podstawie metody equals.
Wszystkie metody implementacji HashSet możesz znaleźć tutaj.
TreeSet
TreeSet oczywiście różni się od HashSet, lecz nieznacznie. Największą różnicą jest to, że TreeSet przechowuje elementy posortowane. Elementy są sortowane na podstawie Comparatora, który możemy zdefiniować na conajmniej dwa sposoby. W obiekcie, który ma być posortowany musimy zaimplementować interfejs Comparable<T>. Możemy również stworzyć klasę implementującą interfejs Comparator<T> i przekazać taki obiekt w konstruktorze Set.
Na wstępie warto podkreślić, że z jakiej metody byśmy nie skorzystali to jesteśmy zmuszeni do zdefiniowania metody compare lub compareTo. Metoda compare przyjmuje dwa obiekty, które będzie porównywać, zaś compareTo tylko jeden ze względu, że operuje na polach w danym obiekcie. Jednak te obie metody mają cechę wspólną, zwracają one bowiem:
- 0, gdy obiekty są równe
- 1, gdy obiekt jest większy
- -1, gdy obiekt jest mniejszy
Comparable<T>
Przy tej metodzie będziemy musieli nanieść poprawki na sam model Participant, musi on bowiem implementować interfejs Comparable. W związku, że implementujemy ten interfejs musimy zaimplementować metodę compareTo(T obj), którą to właśnie będzie używał TreeSet.
public class Participant implements Comparable<Participant>
Tak będzie wyglądał nagłowek naszej klasy, teraz czas zdefiniować metodę compareTo. Przypuśćmy, że uczestnicy będą sortowani względem wieku. Metoda compareTo będzie wtedy wyglądać tak:
@Override
public int compareTo(Participant o) {
return this.age > o.age ? 1 : this.age==o.age ? 0 : -1;
}
Zastosowałem tutaj operator trójargumentowy, można to również zrobić za pomocą instrukcji warunkowej if. W skrócie, jeżeli this.age jest większy niż o.age zwróć 1, jeżeli są równe to zwróci 0, w przeciwnym wypadku (czyli this.age jest mniejszy) zwróci -1.
Nasza klasa Participant wygląda teraz tak:
package pl.maniaq.models;
import java.util.Objects;
public class Participant implements Comparable<Participant> {
private String name;
private int age;
public Participant(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Participant)) return false;
Participant that = (Participant) o;
return getAge() == that.getAge() &&
Objects.equals(getName(), that.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getAge());
}
@Override
public String toString() {
return "Participant{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Participant o) {
return this.age > o.age ? 1 : this.age==o.age ? 0 : -1;
}
}
Przejdźmy teraz do main, zmieńmy tylko implementację z Hash na TreeSet oraz zaimportujmy oczywiście java.util.TreeSet.
package pl.maniaq.collections;
import pl.maniaq.models.Participant;
import java.util.Arrays;
import java.util.Set;
import java.util.TreeSet;
public class Tree {
public static void main(String[] args) {
Set<Participant> participants = new TreeSet<>(Arrays.asList(
new Participant("Franek", 15),
new Participant("Edek", 18),
new Participant("Olek", 19)
));
participants.add(new Participant("Franek", 15));
participants.add(new Participant("Olek", 19));
participants.add(new Participant("Ula", 16));
System.out.println("Lista wszystkich uczestników");
for (Participant participant:participants
) {
System.out.println(participant.toString());
}
System.out.println("Liczba uczestników: "+participants.size());
}
}
Po uruchomieniu takiego programu, otrzymujemy taki wynik.
Lista wszystkich uczestników
Participant{name='Franek', age=15}
Participant{name='Ula', age=16}
Participant{name='Edek', age=18}
Participant{name='Olek', age=19}
Liczba uczestników: 4
Nadal obiekty są unikalne, lecz tym razem są posortowane względem wieku.
Możemy dodatkowo zmienić implementację naszej metody compareTo, aby sortowała malejąco:
@Override
public int compareTo(Participant o) {
return this.age > o.age ? -1 : this.age==o.age ? 0 : 1;
}
I teraz program zachowuje się tak:
Lista wszystkich uczestników
Participant{name='Olek', age=19}
Participant{name='Edek', age=18}
Participant{name='Ula', age=16}
Participant{name='Franek', age=15}
Liczba uczestników: 4
Czyli wszystko po naszej myśli.
Comparator<T>
Gdy nie chcemy implementować interfejsu Comparable<T> w modelu, możemy stworzyć nową klasę, która będzie odpowiedzialna za sortowanie obiektów implementując interfejs Comparator<T>.
Tworzymy, więc nową klasę o nazwie ParticipantComparator. Implementując interfejs Comparator jesteśmy, więc zmuszeni tym razem do implementacji metody compare(T 01, T 02). Na początku, więc nasza klasa wygląda następująco:
package pl.maniaq.comparators;
import pl.maniaq.models.Participant;
import java.util.Comparator;
public class ParticipantComparator implements Comparator<Participant> {
@Override
public int compare(Participant o1, Participant o2) {
return 0;
}
}
Ponownie musimy zdefiniować jak ma przebiegać sortowanie naszych obiektów.
@Override
public int compare(Participant o1, Participant o2) {
int firstAge = o1.getAge();
int secondAge = o2.getAge();
return firstAge > secondAge ? 1 : firstAge == secondAge ? 0 : -1;
}
Zasada ta sama, sortujemy rosnącą względem wiekiem. Przechodzimy do naszej funkcji main i teraz w konstruktorze przekazujemy nasz ParticipantComparator. Dodawanie uczestników poprzez Arrays.asList przeniesiemy do metody add.
package pl.maniaq.collections;
import pl.maniaq.comparators.ParticipantComparator;
import pl.maniaq.models.Participant;
import java.util.Set;
import java.util.TreeSet;
public class Tree {
public static void main(String[] args) {
ParticipantComparator comparator = new ParticipantComparator();
Set<Participant> participants = new TreeSet<>(comparator);
participants.add(new Participant("Franek", 15));
participants.add(new Participant("Olek", 19));
participants.add(new Participant("Ula", 16));
participants.add(new Participant("Franek", 15));
participants.add(new Participant("Edek", 18));
participants.add(new Participant("Olek", 19));
System.out.println("Lista wszystkich uczestników");
for (Participant participant:participants
) {
System.out.println(participant.toString());
}
System.out.println("Liczba uczestników: "+participants.size());
}
}
Czyli mamy już użyty nasz comparator, jednak musimy teraz pamiętać, żeby usunąć implementacji Comparable<T> z klasy Participant – nie jest nam juz w końcu potrzebna. Klasa, więc wygląda ponownie tak:
package pl.maniaq.models;
import java.util.Objects;
public class Participant{
private String name;
private int age;
public Participant(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Participant)) return false;
Participant that = (Participant) o;
return getAge() == that.getAge() &&
Objects.equals(getName(), that.getName());
}
@Override
public int hashCode() {
return Objects.hash(getName(), getAge());
}
@Override
public String toString() {
return "Participant{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Uruchamiając nasz program otrzymujemy taki rezultat:
Lista wszystkich uczestników
Participant{name='Franek', age=15}
Participant{name='Ula', age=16}
Participant{name='Edek', age=18}
Participant{name='Olek', age=19}
Liczba uczestników: 4
Jak widać stworzony przez nas komparator spełnia swoją rolę.
Map<K, V>
Mapa jest specyficzną kolekcją – z tego powodu właśnie nie implementuje interfejsu Collections. Jak zdążyłeś zauważyć odpowiedź prawodopodobnie kryje się, pod typami generycznymi – w poprzednich kolekcjami używaliśmy tylko jednego typu, w przypadku map mamy, aż dwa oznaczone K i V.
Dlaczego się tak różni…
Mapa różni się od innych kolekcji tym, że jest powiazanie klucz (K) -> wartość (V). W wyżej wymienionych kolekcji nie było czegoś takiego jak klucz, wrzucaliśmy po prostu nasze obiekty do konteneru.
Czym są, więc te klucze? Klucze to nic innego jak ID danego obiektu, który musi być unikalny – mapa nie pozwala na dodanie dwóch elementów o tym samym kluczu – jeżeli zaś chcemy tak zrobić to jako wartości musimy użyć jakieś listy, ktora będzie przechowywała N elementów.
Do czego się przydaje?
Mapa się przydaje w sytuacjach, gdy chcemy za wszelką cenę jakiś klucz powiązać z daną wartością. Co możemy być przykładem takiej mapy? A np. miasta, które są przypisane do danego kraju – w tym przypadku to kraj jest kluczem, a miasto wartością. Na tej podstawie można również stworzyć inne powiązania.
Implementacje interfejsu Map
Czytając teorię mapy, niekoniecznie musisz wszystko wiedzieć. Wszystko Ci się wyjaśni, gdy przejdziemy do przykładu, jednak wcześniej sprawdźmy jakie klasy implementują interfejs Map.
W przypadku mapy, pokażę Ci tylko jeden przykłąd na implementacji HashMap – czyli na takiej bardzo podstawowej, jednak krótko omówimy sobie cztery z nich: TreeMap, LinkedHashMap, HashMap, EnumMap.
HashMap
Prosta implementacja mapy, zachowuje się podobnie jak wszystkie implementacje z przedrostkiem Hash.
- Elementy nie są posortowane
- Nie mamy pewności, że elementy są ułożone w kolejności ich dodawania
- Złożoność obliczeniowa podstawowych operacji to O(1) (get, put)
- Pozwala wprowadzić null jako klucz i wartość
Treemap
Podobnie jak wszystkie implementację z przedrostkiem Tree są zbudowane na drzewie binarnym i zachowują się podobnie:
- Elementy są posortowane (musimy zdefiniować nasz comparator za pomocą interfejsów Comparator<T> lub Comparable<T>)
- Operacje dodawanie i wyszukiwania mają złożoność obliczeniową O(ln(n)).
EnumMAP
Osobiście tej implementacji nigdy nie używałem, jednak jest bardzo specyficzna – kluczami w tej mapie mogą być tylko Enumeratory.
- Uniemożliwia wstawienie null jako klucza
- Wartości są przechowywane w kolejności ich dodawania
- Kluczem może być tylko enumerator
LinkedhashMap
Tak samo jak w przypadku listy występuje przedrostek Linked, czyli już zapala nam się w głowie, że elementy są w jakiś sposób ze sobą połączone. Dokładnie LinkedHashMap jest zaimplementowana na podstawi HashTable oraz LinkedList, jakie są z tego korzyści?
- Elementy są przechowywane w kolejności jak były dodawane
- Złożoność podstawowych operacji O(1)
- Możliwość wstawiania nulla
Zastosowanie
Zaimplementujmy sobie prostą mapę – HashMap. Zastosujmy wyżej wymieniony przykład tzn. powiązanie państwo -> miasto. Wszystko można ładnie zrobić na własnych obiektach, które mogłyby przechowywać dodatkowe informacje np. liczbę ludności, język itd. – jednak my zrobimy to na String, aby pokazać samo zastosowanie mapy.
Na początek w main zaimplementujmy sobię HashMapę.
package pl.maniaq.collections;
import java.util.HashMap;
import java.util.Map;
public class MapHash {
public static void main(String[] args) {
Map<String, String> countries = new HashMap<>();
}
}
Czyli mamy już naszą mapę, gdzie naszym kluczem jest Państwo (String), zaś wartością jest Miasto (String). Dodajmy sobie teraz kilka elementów do naszej mapy.
countries.put("POLAND", "WARSAW");
countries.put("RUSSIA", "MOSCOW");
countries.put("BELARUS", "MINSK");
Jak widzisz, do wstawianie elementów do mapy używa się metody put, gdzie pierwszy argument to klucz, drugi zaś to wartość.
Wyświetlmy teraz naszą mapę.
for (Map.Entry<String, String> country : countries.entrySet()
) {
System.out.println("Kraj: "+country.getKey()+ ", miasto: "+country.getValue());
}
W przypadku mapy skorzystaliśmy również z pętli foreach, jednak jesteśmy już zmuszeni do skorzystania z Entry. Map.Entry jest typem, który przechowuje właśnie klucz, wartość. Zaś metoda entrySet(), zwraca nam zbiór takich właśnie par, po którym iterujemy w pętli foreach.
Kod naszego programu wygląda, więc tak:
package pl.maniaq.collections;
import java.util.HashMap;
import java.util.Map;
public class MapHash {
public static void main(String[] args) {
Map<String, String> countries = new HashMap<>();
countries.put("POLAND", "WARSAW");
countries.put("RUSSIA", "MOSCOW");
countries.put("BELARUS", "MINSK");
for (Map.Entry<String, String> country : countries.entrySet()
) {
System.out.println("Kraj: "+country.getKey()+ ", miasto: "+country.getValue());
}
}
}
A rezultat działania programu tak:
Kraj: RUSSIA, miasto: MOSCOW Kraj: POLAND, miasto: WARSAW Kraj: BELARUS, miasto: MINSK
Przyjrzyj się dokładnie otrzymanemu wynikowi, tak jak wcześniej wspominałem nie mamy pewności, że elementy są przechowywane w takiej kolejności jakiej były dodawane.
Możesz poeksperymentować jaki rezultat programu będzie, gdy skorzystasz z LinkedHashMap lub TreeMap.
Na koniec…
Przygotowałem dla Ciebie po jednym zadaniu, abyś mógł przećwiczyć kolekcje.
- Napisz klasę City, która będzie przechowywała nazwę miasta, liczbę mieszkańców oraz powierzchnię miasta. Korzystając z interfejsu List stwórz listę miast. Zastanów się w jakim przypadku lepiej będzie wykorzystać implementację LinkedList, a kiedy ArrayList. Wynik programu wyświetl na ekran konsoli..
- Napisz klasę Color, która będzie przechowywała wartości RGB. Następnie utwórz zbiór TreeSet oraz zdefiniuj swój Comparator dla kolorów – sam wybierz w jaki sposób ma sortować kolory. Wynik programu wyświetl na ekran konsoli.
- Napisz klasę Country, która będzie przechowywała nazwę państwa, liczbę ludności oraz język urzędowy. Korzystając z HashMap, stwórz mapę, gdzie kluczem będzie obiekt Country, zaś wartością będzie lista obiektów City (z zadania nr.1). Wynik programu wyświetl na ekran konsoli. Dodatkowo zapisz mapę do pliku w formacie:
[nazwa państwa] - liczba ludnosci - jezyk urzedowy 1. nazwa miasta - liczba mieszkanców - powierzchnia miasta 2. nazwa miasta - liczba mieszkanców - powierzchnia miasta 3. nazwa miasta - liczba mieszkanców - powierzchnia miasta
Jeżeli masz jakikolwiek z rozwiązaniem wyżej wymienionych zadań napisz w komentarzu, a postaram Ci się pomóc.